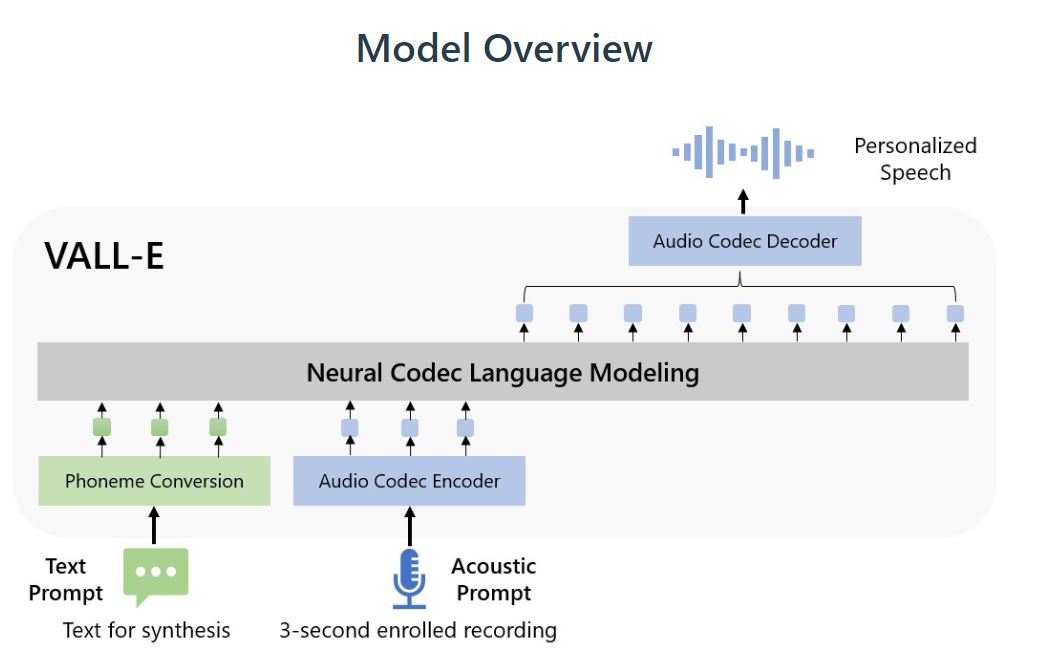
Microsoftovi istraživači prošlog tjedna predstavili su VALL-E - model umjetne inteligencije koji pretvara tekst u određenu intonaciju govora.
Modela koji pretvaraju tekst u govor ima puno, a postoje i oni koji imitiraju određeni glas, no ono po čemu je VALL-E poseban je sposobnost da imitira nečiji glas na temelju uzorka od samo tri sekunde. Kako to izgleda u praksi, može se vidjeti na web prezentaciji koja uključuje i niz snimki govora.
Prvi, Speaker prompt predstavlja uzorak u trajanju samo tri sekunde koji je umjetnoj inteligenciji poslužio za analizu nečijeg govora. VALL-E na osnovu tog uzorka izgovara zadanu rečenicu (u prezentaciji je napisana s lijeve strane). Kako bi se moglo procijeniti koliko je uspješno zadatak obavljen, objavljen je i Ground Truth - način na koji tu rečenicu izgovara izvorni govornik te Baseline - način na koji tu rečenicu izgovara konkurentski model pretvarača teksta u govor sličan nečijem glasu.
Dodatni uzorci u prezentaciji pokazuju kako se VALL-E može ponuditi snimku s odgovarajućim akustičnim okruženjem, a može se prilagoditi i različitim načinima emocionalnog izgovaranja poput ljutitog ili pospanog tona.
Više informacija o modelu može se pronaći u spomenutoj prezentaciji, a osnovni način njegovog rada može se vidjeti i u donjem prikazu. Niz je načina na koji bi se ovaj softver mogao primijeniti, a osim dobronamjernih, moguće su i zlonamjerni poput imitiranja nečijeg glasa bez pristanka te osobe ili modificiranja snimki mijenjanjem nekih dijelova.